






 BTC/HKD+0.61%
BTC/HKD+0.61% ETH/HKD+0.69%
ETH/HKD+0.69% LTC/HKD+0.88%
LTC/HKD+0.88% DOT/HKD-0.02%
DOT/HKD-0.02% ADA/HKD+0.32%
ADA/HKD+0.32% SOL/HKD+0.41%
SOL/HKD+0.41% XRP/HKD+0.77%
XRP/HKD+0.77% DOGE/US+1.15%
DOGE/US+1.15%撰文:Tanya Malhotra
來源:Marktechpost
編譯:DeFi 之道

圖片來源:由無界版圖AI工具生成
隨著生成性人工智能在過去幾個月的巨大成功,大型語言模型(LLM)正在不斷改進。這些模型正在為一些值得注意的經濟和社會轉型做出貢獻。OpenAI 開發的 ChatGPT 是一個自然語言處理模型,允許用戶生成有意義的文本。不僅如此,它還可以回答問題,總結長段落,編寫代碼和電子郵件等。其他語言模型,如 Pathways 語言模型(PaLM)、Chinchilla 等,在模仿人類方面也有很好的表現。
BNB Chain將于3月6日贊助創新黑客松,將分為去中心化存儲系統等類別:2月18日,據官方消息,BNB Chain宣布將于3月6日在沙特阿拉伯利雅得舉行的Web3 Delight會議期間贊助了一場創新黑客松(Innovation Hackathon)。
據悉,此次創新黑客松的類別分為去中心化存儲系統、Web3聲譽、去中心化社會、實時數據索引、安全錢包、Web3 Streaming、Web3中的最佳路由等。[2023/2/18 12:15:08]
大型語言模型使用強化學習(reinforcement learning,RL)來進行微調。強化學習是一種基于獎勵系統的反饋驅動的機器學習方法。代理(agent)通過完成某些任務并觀察這些行動的結果來學習在一個環境中的表現。代理在很好地完成一個任務后會得到積極的反饋,而完成地不好則會有相應的懲罰。像 ChatGPT 這樣的 LLM 表現出的卓越性能都要歸功于強化學習。
Etherscan創始團隊推出“以太坊即時通訊應用”Blockscan Chat:金色財經報道,Etherscan 區塊鏈瀏覽器的團隊 Blockscan 發布了 Blockscan Chat 測試版。根據該網站主頁披露的信息顯示,“Blockscan Chat 是一個消息傳遞平臺,用戶可以通過錢包到錢包輕松、即時地相互發送消息,網站上寫道,”要使用它,您必須連接到 MetaMask 等以太坊錢包。具有以太坊地址的消息接收者將通過區塊瀏覽器收到通知(盡管該消息不會在區塊瀏覽器上公開)。” 一些社區用戶已經將該工具非正式地稱為“Ethereum Instant Messenger”, Bankless 的 Ryan Sean Adams 表示,你甚至可以用這款工具與黑客進行交流,在試圖協商資金返還的情況下這款工具很有用,不過也有人指出,雖然這款工具使用了Web 3技術,但似乎還沒有實現完全去中心化。[2022/1/26 9:13:34]
ChatGPT 使用來自人類反饋的強化學習(RLHF),通過最小化偏差對模型進行微調。但為什么不是監督學習(Supervised learning,SL)呢?一個基本的強化學習范式由用于訓練模型的標簽組成。但是為什么這些標簽不能直接用于監督學習方法呢?人工智能和機器學習研究員 Sebastian Raschka 在他的推特上分享了一些原因,即為什么強化學習被用于微調而不是監督學習。
公告 | Blockchain錢包宣布將不再支持BSV:4月15日,Blockchain.com發布公告稱,決定在2019年5月15日之前終止Blockchain錢包對BSV的所有支持。[2019/4/16]
不使用監督學習的第一個原因是,它只預測等級,不會產生連貫的反應;該模型只是學習給與訓練集相似的反應打上高分,即使它們是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量,而不僅僅是排名分數。
JoorsChain數字廣告鏈基石輪順利完成:JoorsChain數字廣告鏈基石輪順利完成,獲得來自Y Investment、千方基金、G?del labs、世通資本、寰宇資本、加密資本 、至臻資本、陌思投資、海納投資、首聯投資 、華迎資本、樂米投資等數十家機構投資。JoorsChain的Dapp每月出廠預裝200萬安卓手機,將重塑數字廣告產業價值。 JoorsChain目前推特關注4719人,電報群6715人,微信官方及粉絲群95個共20000+人。[2018/6/8]
Sebastian Raschka 分享了使用監督學習將任務重新表述為一個受限的優化問題的想法。損失函數結合了輸出文本損失和獎勵分數項。這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題-答案對時才能成功。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話也是必要的,而監督學習無法提供這種獎勵。
不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的。
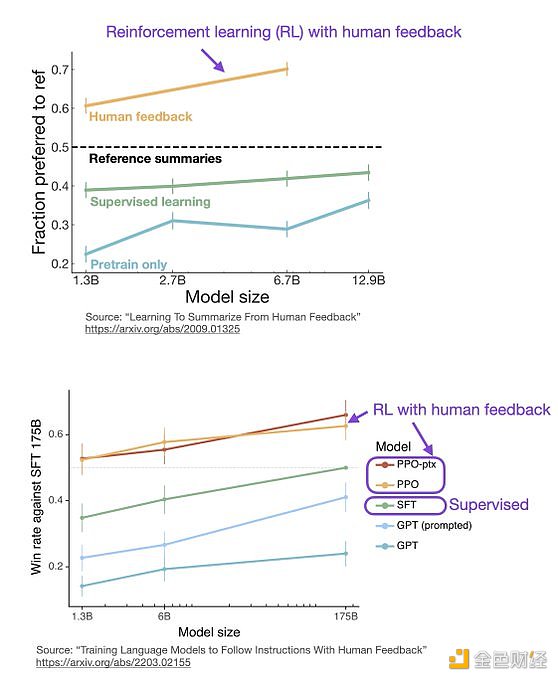
監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好。2022 年的一篇論文《從人類反饋中學習總結》顯示,RLHF 比 SL 表現得更好。原因是 RLHF 考慮了連貫性對話的累積獎勵,而 SL 由于其文本段落級的損失函數而未能很好做到這一點。
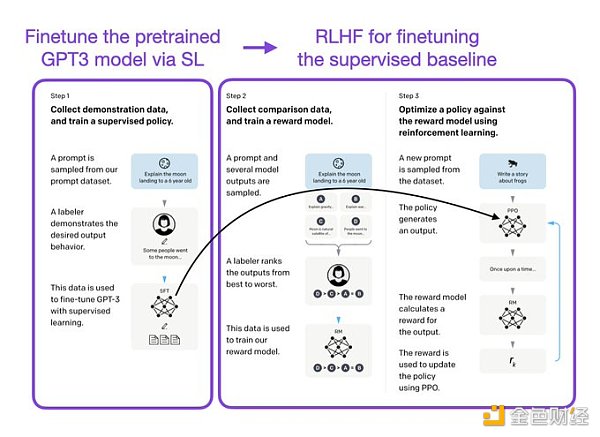
像 InstructGPT 和 ChatGPT 這樣的 LLMs 同時使用監督學習和強化學習。這兩者的結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,然后使用 RL 進一步更新。SL 階段允許模型學習任務的基本結構和內容,而 RLHF 階段則完善模型的反應以提高準確性。
DeFi之道
個人專欄
閱讀更多
金色財經 善歐巴
金色早8點
Odaily星球日報
歐科云鏈
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新聞
Tags:CHAAINChainHAIchain幣是什么幣ipcchainFLOKICHAIN幣dongdongchain
作者:Chloe 全球規模最大的crypto會議ETHDenver昨天剛結束,今年參加人數超過30000多人,是有史以來人數最多的一次,完全不受行業各種暴雷事件的影響.
1900/1/1 0:00:00原文作者 :Thor Hartvigsen 原文編譯 :白澤研究院 誰秘密地持有你感興趣的協議的大部分代幣?他們以什么價格投資/買入?DeFi 研究員 Thor Hartvigsen 根據自創的.
1900/1/1 0:00:00文章來源:SophonLabs原文標題:《加密投資者必備 Opsec 指南》在這篇文章中,我們將討論如何修改日常在線的操作細節以提高 opsec(操作安全性).
1900/1/1 0:00:00撰文:Salazar.eth編譯:0x11,Foresight News我們都知道 zkEVM 是什么,但它是如何與以太坊基礎層交互的呢?這是一個對初學者友好的 zkEVM 工作流程.
1900/1/1 0:00:00作者:Frogs Anon 編譯:DeFi 之道 毫無疑問,自 Compound 在 2020 年啟動 DeFi 夏季以來,DeFi 已經取得了長足的進步.
1900/1/1 0:00:001.金色觀察 | 8個問題讀懂Yuga Labs將發行的比特幣NFT TwelveFold比特幣NFT的火熱,終于讓以太坊上的藍籌NFT項目方坐不住了.
1900/1/1 0:00:00


