






 BTC/HKD+1.34%
BTC/HKD+1.34% ETH/HKD+1.74%
ETH/HKD+1.74% LTC/HKD+0.4%
LTC/HKD+0.4% DOT/HKD+1.43%
DOT/HKD+1.43% ADA/HKD+1.69%
ADA/HKD+1.69% SOL/HKD+5.32%
SOL/HKD+5.32% XRP/HKD+1.49%
XRP/HKD+1.49% DOGE/US+1.5%
DOGE/US+1.5%導讀
首先問大家一個小問題?區塊鏈的賬本數據存儲格式主要是什么類型的?
相信聰明的你一定知道是Key-Value類型存儲。
下一個問題,這些Key-Value數據在底層數據庫如何高效組織?
答案就是我們本期介紹的內容:LSM。
LSM是一種被廣泛采用的持久化Key-Value存儲方案,如LevelDB,RocksDB,Cassandra等數據庫均采用LSM作為其底層存儲引擎。
據公開數據調研,LSM是當前市面上寫密集應用的最佳解決方案,也是區塊鏈領域被應用最多的一種存儲模式,今天我們將對LSM基本概念和性能進行介紹和分析。
LSM-Tree背景:追本溯源
LSM-Tree的設計思想來自于一個計算機領域一個老生常談的話題——對存儲介質的順序操作效率遠高于隨機操作。
如圖1所示,對磁盤的順序操作甚至可以快過對內存的隨機操作,而對同一類磁盤,其順序操作的速度比隨機操作高出三個數量級以上,因此我們可以得出一個非常直觀的結論:應當充分利用順序讀寫而盡可能避免隨機讀寫。
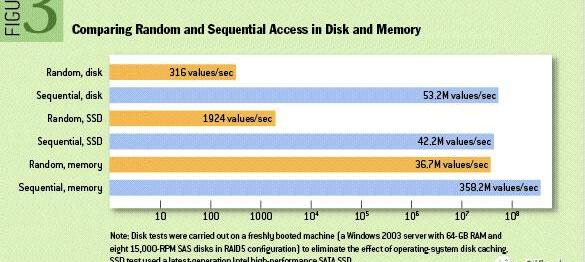
Figure1Randomaccessvs.Sequentialaccess
全國政協委員:運用區塊鏈等技術 發揮信息化在疾控工作中的支撐作用:全國政協委員、杭州市政協副主席謝雙成表示,從這次疫情來看,我國公共衛生應急戰略規劃和投入保障不足,法治和信息化建設比較滯后,人才短缺,基層衛生網的建設較為薄弱。他建議,依托醫養護平臺及公共衛生平臺建設,打通“信息孤島”,深度融合醫療服務信息、公共衛生基礎信息、部門數據,運用區塊鏈、大數據、人工智能、云計算、物聯網等技術,發揮信息化在疾控工作中的重要支撐作用。(經濟參考報)[2020/5/29]
考慮到這一點,如果我們想盡可能提高寫操作的吞吐量,那么最好的方法一定是不斷地將數據追加到文件末尾,該方法可將寫入吞吐量提高至磁盤的理論水平,然而也有顯而易見的弊端,即讀效率極低,我們稱這種數據更新是非原地的,與之相對的是原地更新。
為了提高讀取效率,一種常用的方法是增加索引信息,如B+樹,ISAM等,對這類數據結構進行數據的更新是原地進行的,這將不可避免地引入隨機IO。
LSM-Tree與傳統多叉樹的數據組織形式完全不同,可以認為LSM-Tree是完全以磁盤為中心的一種數據結構,其只需要少量的內存來提升效率,而可以盡可能地通過上文提到的Journaling方式來提高寫入吞吐量。當然,其讀取效率會稍遜于B+樹。
新韓金融集團布局數字核心技術 旗下Orange Life將主導區塊鏈業務:據韓聯社消息,3月23日,新韓金融集團宣布其首席執行官趙永炳將推出直接管理數字核心技術的“數字監護人系統”。新韓金融集團選擇未來需要的數字核心技術,并指定一個監護集團公司,且該集團的CEO將成為監護人并領導該項數字核心業務。其中,新韓金融集團旗下公司Orange Life被選為區塊鏈板塊業務。[2020/3/23]
LSM-Tree數據結構:抽絲剝繭
圖2展示了LSM-Tree的理論模型(a)和一種實現方式(b)。LSM-Tree是一種層級的數據結構,包含一層空間占用較小的內存結構以及多層磁盤結構,每一層磁盤結構的空間上限呈指數增長,如在LevelDB中該系數默認為10。
Figure2LSM與其LevelDB實現
對于LSM-Tree的數據插入或更新,首先會被緩存在內存中,這部分數據往往由一顆排序樹進行組織。
當緩存達到預設上限,則會將內存中的數據以有序的方式寫入磁盤,我們稱這樣的有序列為一個SortedRun,簡稱為Run。
隨著寫入操作的不斷進行,L0層會堆積越來越多的Run,且顯然不同的Run之前可能存在重疊部分,此時進行某一條數據的查詢將無法準確判斷該數據存在于哪個Run中,因此最壞情況下需要進行等同于L0層Run數量的I/O。
為了解決該問題,當某一層的Run數目或大小到達某一閾值后,LSM-Tree會進行后臺的歸并排序,并將排序結果輸出至下一層,我們將一次歸并排序稱為Compaction。如同B+樹的分裂一樣,Compaction是LSM-Tree維持相對穩定讀寫效率的核心機制,我們將會在下文詳細介紹兩種不同的Compaction策略。
聲音 | John McAfee:比特幣是古老的技術 會像福特T型車一樣被取代:JohnMcAfee此前曾預測比特幣到2020年底將價值100萬美元。McAfee最近發推表示,成為第一個區塊鏈并不意味著比特幣就是“未來”。在他看來,比特幣是古老的技術,而更新的區塊鏈具有增強的功能,可以解決比特幣區塊鏈的缺陷,就像1908年的福特T型車被更復雜的汽車取代一樣。[2020/1/6]
另外值得一提的是,無論是從內存到磁盤的寫入,還是磁盤中不斷進行的Compaction,都是對磁盤的順序I/O,這就是LSM擁有更高寫入吞吐量的原因。
Levelingvs.Tiering:一讀一寫,不分伯仲
LSM-Tree的Compaction策略可以分為Leveling和Tiering兩種,前者被LevelDB,RocksDB等采用,后者被Cassandra等采用,稱采用Leveling策略的的LSM-Tree為LeveledLSM-Tree,采用Tiering的LSM-Tree為TieredLSM-Tree,如圖3所示。
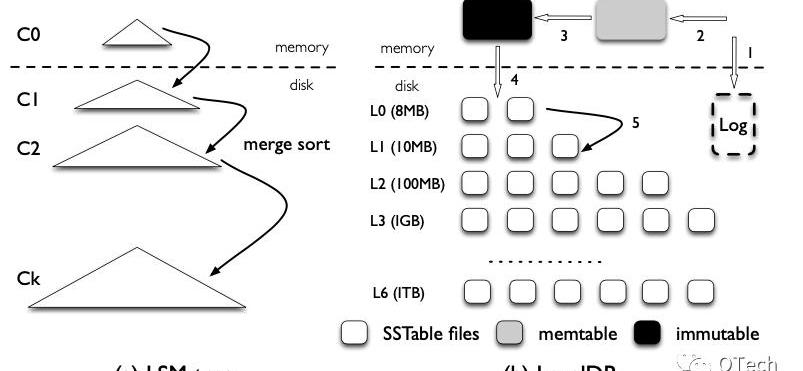
Figure3兩種Compaction策略對比
▲Leveling
簡而言之,Tiering是寫友好型的策略,而Leveling是讀友好型的策略。在Leveling中,除了L0的每一層最多只能有一個Run,如圖3右側所示,當在L0插入13時,觸發了L0層的Compaction,此時會對Run-L0與下層Run-L1進行一次歸并排序,歸并結果寫入L1,此時又觸發了L1的Compaction,此時會對Run-L1與下層Run-L2進行歸并排序,歸并結果寫入L2。
聲音 | 劉東:希望企業能更多關注區塊鏈技術 真正實現數字經濟:據人民網消息,阿里集團新零售技術群資深專家、埃森哲大中華區技術創新官劉東在2019中國紡織創新年會主題演講中表示,數字技術不再是差異化競爭優勢,已成為企業制勝未來的必備要素。企業能更多關注區塊鏈技術,在未來,能與生態系統內所有玩家鏈動,真正實現數字經濟。[2019/7/10]
▲Tiering
反觀Tiering在進行Compaction時并不會主動與下層的Run進行歸并,而只會對發生Compaction的那一層的若干個Run進行歸并排序,這也是Tiering的一層會存在多個Run的原因。
▲對比分析
相比而言,Leveling方式進行得更加貪婪,進行了更多的磁盤I/O,維持了更高的讀效率,而Tiering則相正好反。
本節我們將對LSM-Tree的設計空間進行更加形式化的分析。
LSM層數

布隆過濾器
LSM-Tree應用布隆過濾器來加速查找,LSM-Tree為每個Run設置一個布隆過濾器,在通過I/O查詢某個Run之前,首先通過布隆過濾器判斷待查詢的數據是否存在于該Run,若布隆過濾器返回Negative,則可斷言不存在,直接跳到下個Run進行查詢,從而節省了一次I/O;而若布隆過濾器返回Positive,則仍不能確定數據是否存在,需要消耗一次I/O去查詢該Run,若成功查詢到數據,則終止查找,否則繼續查找下一個Run,我們稱后者為假陽現象,布隆過濾器的過高的假陽率會嚴重影響讀性能,使得花費在布隆過濾器上的內存形同虛設。限于篇幅本文不對布隆過濾器做更多的介紹,直接給出FPR的計算公式,為公式2.
動態 | 鋼鐵電商積微物聯引入區塊鏈等新技術 打造“鋼鐵大腦”:據經濟參考報消息,西南最大鋼鐵電商、全國最大物流綜合體積微物聯。面向全國布局線下業務,構建積微循環、積微云采等線下平臺,牽手清華大學、電子科大、阿里、浙大網新等知名高校和企業,引入大數據、人工智能、區塊鏈等新技術,打造“鋼鐵大腦”,推進傳統制造業的兩化深度融合,形成了以積微物聯為核心的工業互聯網生態圈,趟出了一條發展新經濟、新業態、新模式的新路子。[2018/11/5]
其中是為布隆過濾器設置的內存大小,為每個Run中的數據總數。讀寫I/O
考慮讀寫操作的最壞場景,對于讀操作,認為其最壞場景是空讀,即遍歷每一層的每個Run,最后發現所讀數據并不存在;對于寫操作,認為其最壞場景是一條數據的寫入會導致每一層發生一次Compaction。
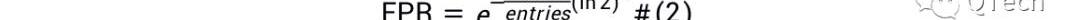
核心理念:基于場景化的設計空間
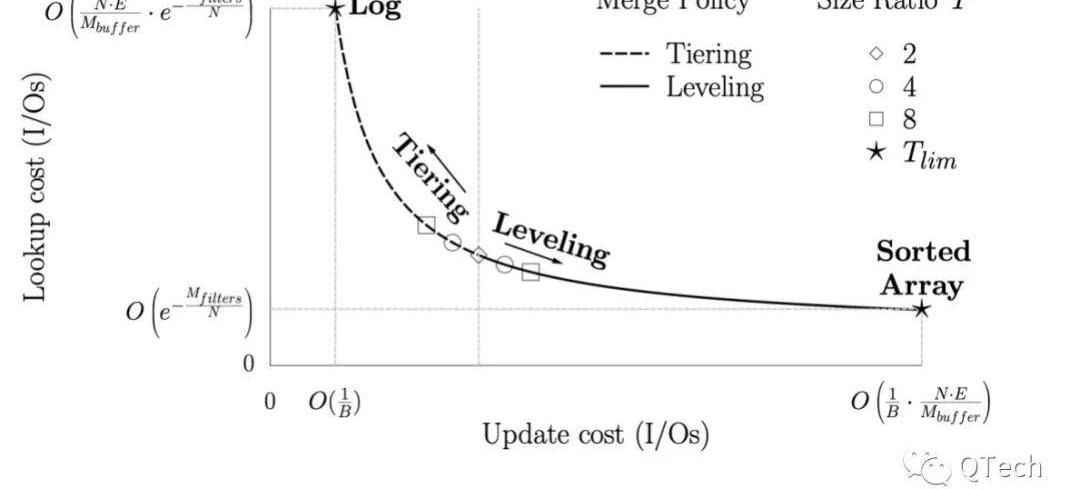
基于以上分析,我們可以得出如圖4所示的LSM-Tree可基于場景化的設計空間。
簡而言之,LSM-Tree的設計空間是:在極端優化寫的日志方式與極端優化讀的有序列表方式之間的折中,折中策略取決于場景,折中方式可以對以下參數進行調整:

當Level間放大比例時,兩種Compaction策略的讀寫開銷是一致的,而隨著T的不斷增加,Leveling和Tiering方式的讀開銷分別提高/減少。
當T達到上限時,前者只有一層,且一層中只有一個Run,因此其讀開銷到達最低,即最壞情況下只需要一次I/O,而每次寫入都會觸發整層的Compaction;
而對于后者當T到達上限時,也只有一層,但是一層中存在:

因此讀開銷達到最高,而寫操作不會觸發任何的Compaction,因此寫開銷達到最低。
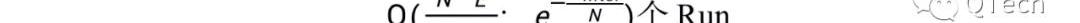
Figure4LSM由日志到有序列的設計空間
事實上,基于圖4及上文的分析可以進行對LSM-Tree的性能進一步的優化,如文獻對每一層的布隆過濾器大小進行動態調整,以充分優化內存分配并降低FPR來提高讀取效率;文獻提出“LazyLeveling”方式來自適應的選擇Compaction策略等。
限于篇幅本文不再對這些優化思路進行介紹,感興趣的讀者可以自行查閱文獻。
小結
LSM-Tree提供了相當高的寫性能、空間利用率以及非常靈活的配置項可供調優,其仍然是適合區塊鏈應用的最佳存儲引擎之一。
本文對LSM-Tree從設計思想、數據結構、兩種Compaction策略幾個角度進行了由淺入深地介紹,限于篇幅,基于本文之上的對LSM-Tree的調優方法將會在后續文章中介紹。
作者簡介葉晨宇來自趣鏈科技基礎平臺部,區塊鏈賬本存儲研究小組
參考文獻
.O’NeilP,ChengE,GawlickD,etal.Thelog-structuredmerge-tree(LSM-tree).ActaInformatica,1996,33(4):351-385.
.JacobsA.Thepathologiesofbigdata.CommunicationsoftheACM,2009,52(8):36-44.
.LuL,PillaiTS,GopalakrishnanH,etal.Wisckey:Separatingkeysfromvaluesinssd-consciousstorage.ACMTransactionsonStorage(TOS),2017,13(1):1-28.
.DayanN,AthanassoulisM,IdreosS.Monkey:Optimalnavigablekey-valuestore//Proceedingsofthe2017ACMInternationalConferenceonManagementofData.2017:79-94.
.DayanN,IdreosS.Dostoevsky:Betterspace-timetrade-offsforLSM-treebasedkey-valuestoresviaadaptiveremovalofsuperfluousmerging//Proceedingsofthe2018InternationalConferenceonManagementofData.2018:505-520.
.LuoC,CareyMJ.LSM-basedstoragetechniques:asurvey.TheVLDBJournal,2020,29(1):393-418.
Tags:TREERUNINGIONTREEB幣Drunk Skunks DCbikingforscience翻譯Ki Foundation
澎湃新聞記者:葉映荷來源:澎湃新聞編者按:數字人民幣的試點進展備受期待。從中國人民銀行成立專門研究團隊到現在已過去6年,數字人民幣真容初露,目前已在深圳、蘇州、雄安、成都等地試點測試.
1900/1/1 0:00:00以太坊上的NFT指數基金NFTX宣布已解鎖用戶在社區募集期間收到的NFTX代幣,并在Uniswap上啟動NFTX/ETH池,起始價格為1枚ETH等于40枚NFTX.
1900/1/1 0:00:00我體驗了一段時間的技術分析之后,并沒有達到自己預期的效果,并且在這個體驗的過程中越來越對這個方式比較抗拒,于是我開始尋找其它的途徑.
1900/1/1 0:00:00編者按:問世十年的區塊鏈技術已經「脫虛向實」。歷經重重迷思后,找到區塊鏈「殺手級」應用成為新的焦點。溯源、存證、供應鏈金融、司法、對賬等等,我們已經看到很多嘗試.
1900/1/1 0:00:00據TheBlockCrypto12月17日報道,管理著價值約40億美元資產的比利時主權財富基金SRIWGroup剛剛投資了區塊鏈風險投資公司TiogaCapital.
1900/1/1 0:00:002021年1月21日,最高人民法院發布《關于人民法院在線辦理案件若干問題的規定》,共計36個條文,其中有4個條文與區塊鏈證據適用有關,分別為第十四條、第十五條、第十六條和第十七條.
1900/1/1 0:00:00


