






 BTC/HKD+0.19%
BTC/HKD+0.19% ETH/HKD+0.42%
ETH/HKD+0.42% LTC/HKD+0.92%
LTC/HKD+0.92% DOT/HKD+4.63%
DOT/HKD+4.63% ADA/HKD-1.34%
ADA/HKD-1.34% SOL/HKD+1.87%
SOL/HKD+1.87% XRP/HKD-1.1%
XRP/HKD-1.1% DOGE/US+1.31%
DOGE/US+1.31%作者:@於方仁@CarolineSun
編排:@黑羽小斗
LLM
大型語言模型是利用海量的文本數據進行訓練海量的模型參數。大語言模型的使用,大體可以分為兩個方向:
A.僅使用
B.微調后使用
僅使用又稱Zero-shot,因為大語言模型具備大量通用的語料信息,量變可以產生質變。即使Zero-shot也許沒得到用戶想要的結果,但加上合適的prompt則可以進一步獲取想要的知識。該基礎目前被總結為promptlearning。
大語言模型,比較流行的就是BERT和GPT。從生態上講BERT與GPT最大的區別就是前者模型開源,后者只開源了調用API,也就是目前的ChatGPT。
兩個模型均是由若干層的Transformer組成,參數數量等信息如下表所示。
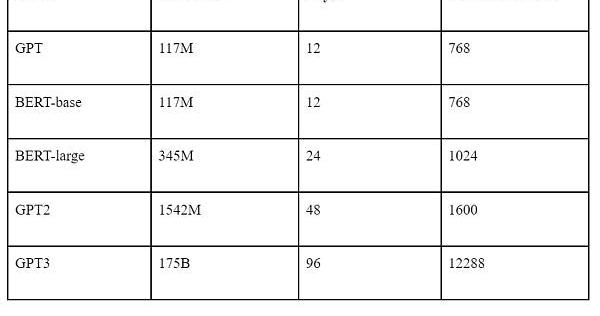
目前生態上講,BERT多用于微調場景。因為微調必須在開源模型的基礎上,GPT僅開源到GPT2的系列。且相同模型參數量下BERT在特定場景的效果往往高于GPT,微調需要調整全部的模型參數,所以從性價比而言,BERT比GPT更適合微調。
而GPT目前擁有ChatGPT這種面向廣大人民群眾的應用,使用簡單。API的調用也尤其方便。所以若是僅使用LLM,則ChatGPT顯然更有優勢。
ChatGPTPrompt
a16z合伙人Chris Dixon推出新書Read Write Own: Building the Next Era of the Internet:6月23日消息,a16z合伙人Chris Dixon撰文介紹新書Read Write Own: Building the Next Era of the Internet,稱這本書回顧了互聯網的歷史,展示了它如何經歷了三個主要的設計時代:第一個關注民主化信息(閱讀),第二個關注民主化出版(寫作),第三個關注民主化所有權(擁有)。
Dixon表示,這本書回答了一個常見問題,“區塊鏈解決了哪些問題?”區塊鏈解決了其他數字服務所解決的問題,但結果更好。它們可以將人們連接在社交網絡中,同時賦予用戶權力,超越了企業的利益。它們可以支持市場和支付系統,促進商業交易,而手續費始終較低。它們可以實現可盈利的媒體形式,互操作性和沉浸式的數字世界,以及補償創作者和社區的人工智能服務,而不是吞噬它們。[2023/6/23 21:56:02]
下圖是OpenAI官方提出對于ChatGPT的prompt用法大類。
Figure1.PromptCategoriesbyOpenAI?
每種類別有很多具體的范例。如下圖所示:
LayerZero生態全鏈NFT協議Holograph開放Building NFT限時免費多鏈鑄造活動:6月14日消息,據官方消息,LayerZero生態全鏈NFT協議Holograph開放BuildingNFT限時免費多鏈鑄造活動。據悉,Building出自藝術家Amber Vittoria之手,可在以太坊、Polygon、Avalanche、BNB Chain和Optimism上免費鑄造,限時48小時(將于1天9小時后結束)。[2023/6/14 21:36:17]
Figure2.PromptCategoriesExamplesbyOpenAI
除此以外,我們在此提出一些略微高級的用法。
高級分類
這是一個意圖識別的例子,本質上也是分類任務,我們指定了類別,讓ChatGPT判斷用戶的意圖在這
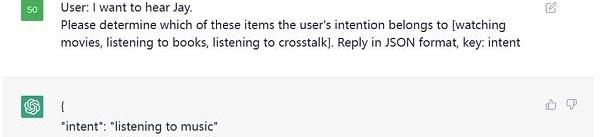
Figure3.PromptExamples
實體識別與關系抽取
利用ChatGPT做實體識別與關系抽取輕而易舉,例如給定一篇文本后,這么像它提問。
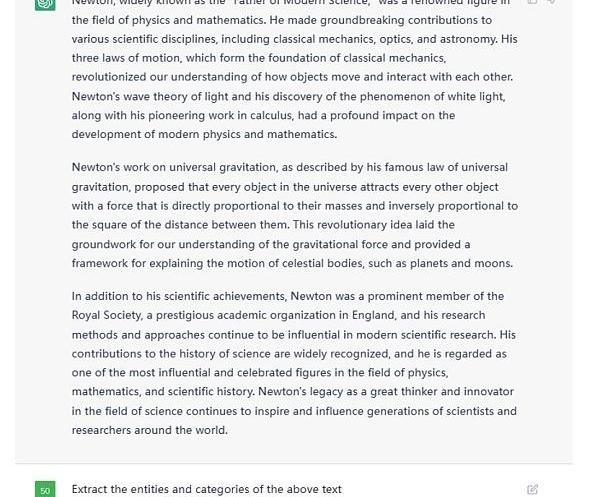
Figure4.ExampleTextGiventoChatGPT
這是部分結果截圖:
DeFi合成資產協議Linear Finance上線Buildr測試網:DeFi合成資產協議Linear Finance(LINA)上線 Buildr測試網 ,Buildr測試網是Linear Finance核心產品的一部分,旨在讓用戶測試Buildr,盡可能多地找到Bug和可以優化的地方,報告給團隊,從讓團隊能夠在上線主網時修正這些問題。團隊將為成功提交反饋意見和Bug報告的用戶提供Bug賞金和LINA獎勵。[2020/10/16]
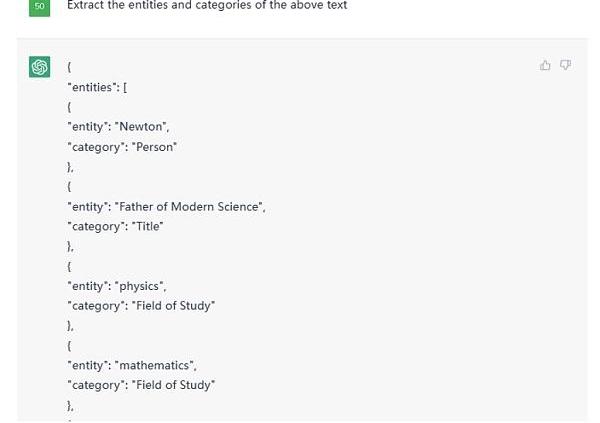
Figure5.PartialOutputfromgivenTextonChatGPT
之后可以追問給他們的關系,例如:

Figure6.AskingrelationshiponChatGPT
這樣,一個大型的知識圖譜便可輕松建立。
分析任務
如下圖所示,我對ChatGPT提出了分析我目前需求的問題。
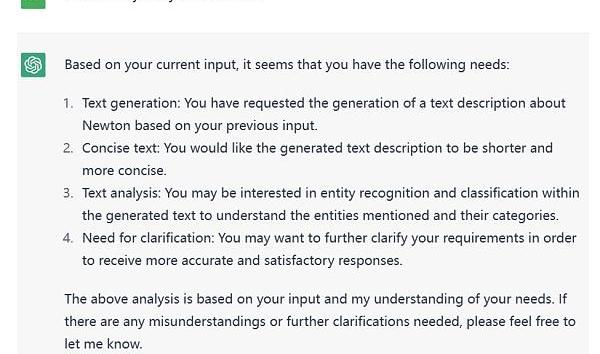
Figure7.ResultforneedsrequestonChatGPT
現場 | 金色財經歐洲游學團隊參加巴黎區塊鏈周分場Building the New Web:金色財經歐洲游學團隊參加了Paris Blockchain Week中的Building New Web分場會議,參加會議的包括Algorand首席工程師Naveed Ihsanullah, GEO Protocol首席架構師Dima Chizhevsky, Solana業務拓展主管Dominic Tsang, Chromapolis聯合創始人Henrik Hjelte,參加了本次會議,嘉賓從加密算法、共識機制、可擴展性、安全性以及鏈上治理等多個角度進行了討論。[2019/4/15]
甚至還能讓它給定分數。

Figure8.Scoringtoevaluatetheidentifiedneeds
除此以外還有數不勝數的方式,在此不一一列舉。
組合Agent
另外,我們在使用ChatGPT的API時,可以將不同的prompt模板產生多次調用產生組合使用的效果。我愿稱這種使用方式叫做,組合Agent。例如Figure1展示的是一個大概的思路。
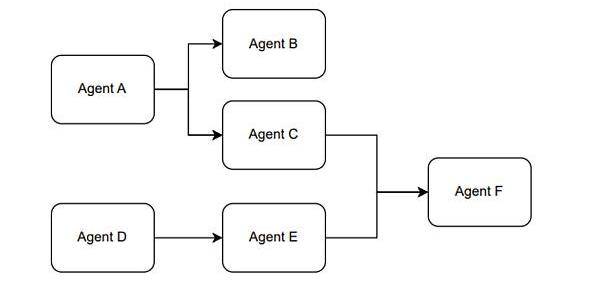
Figure9.?TheParadigmoftheCombinationAgent
現場 | DIGIBUILD聯合創始人:2026年后將見證區塊鏈行業成熟:據cointime.com現場報道,今日在2018西雅圖區塊鏈大會上,DIGIBUILD聯合創始人兼首席執行官Robert Salvador表示,區塊鏈可以通過釋放資金,降低交易成本,加快流程和提供安全性和信任使企業受益。 Salvador預測,2018年到2020年,整個行業將繼續推出加密用例,進行更多的案例研究和早期采用;2021年到2025年,早期采用者和標準活動將提供更大的清晰度,并最大限度地減少不確定性,這將推動廣泛的采用; 2026年及以后將見證區塊鏈行業的成熟,區塊鏈將被廣泛采用并被視為供應鏈和生態系統的一個組成部分。[2018/8/22]
具體說來,例如是一個輔助創作文章的產品。則可以這么設計,如Figure10所示。
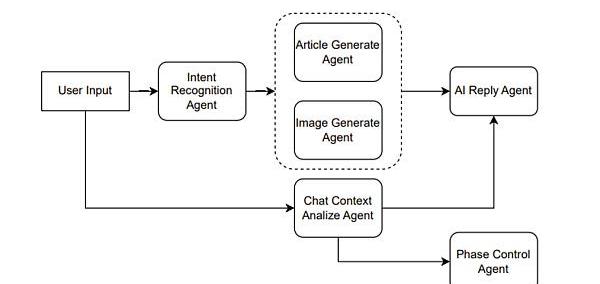
Figure10.Agentcombinationforassistingincreation
假設用戶輸入一個請求,說“幫我寫一篇倫敦游記”,那么IntentRecognitionAgent首先做一個意圖識別,意圖識別也就是利用ChatGPT做一次分類任務。假設識別出用戶的意圖是文章生成,則接著調用ArticleGenerateAgent。
另一方面,用戶當前的輸入與歷史的輸入可以組成一個上下文,輸入給ChatContextAnalyzeAgent。當前例子中,這個agent分析出的結果傳入后面的AIReplyAgent和PhaseControlAgent的。
AIReplyAgent就是用來生成AI回復用戶的語句,假設我們的產品前端并不只有一個文章,另一個敵方還有一個框用來顯示AI引導用戶創作文章的語句,則這個AIReplyAgent就是用來干這個事情。將上下文的分析與文章一同提交給ChatGPT,讓其根據分析結果結合文章生成一個合適的回復。例如通過分析發現用戶只是在通過聊天調整文章內容,而不知道AI還能控制文章的藝術意境,則可以回復用戶你可以嘗試著對我說“調整文章的藝術意境為非現實主義風格”。
PhaseControlAgent則是用來管理用戶的階段,對于ChatGPT而言也可以是一個分類任務,例如階段分為等等。例如AI判斷可以進行文章模板的制作了,前端可以產生幾個模板選擇的按鈕。
使用不同的Agent來處理用戶輸入的不同任務,包括意圖識別、ChatContext分析、AI回復生成和階段控制,從而協同工作,為用戶生成一篇倫敦游記的文章,提供不同方面的幫助和引導,例如調整文章的藝術意境、選擇文章模板等。這樣可以通過多個Agent的協作,使用戶獲得更加個性化和滿意的文章生成體驗。?
Prompt微調
LLM雖然很厲害,但離統治人類的AI還相差甚遠。眼下有個最直觀的痛點就是LLM的模型參數太多,基于LLM的模型微調變得成本巨大。例如GPT-3模型的參數量級達到了175Billion,只有行業大頭才有這種財力可以微調LLM模型,對于小而精的公司而言該怎么辦呢。無需擔心,算法科學家們為我們創新了一個叫做prompttuning的概念。
Prompttuning簡單理解就是針對prompt進行微調操作,區別于傳統的fine-tuning,優勢在于更快捷,prompttuning僅需微調prompt相關的參數從而去逼近fine-tuning的效果。

Figure11.Promptlearning
什么是prompt相關的參數,如圖所示,prompttuning是將prompt從一些的自然語言文本設定成了由數字組成的序列向量。本身AI也會將文本從預訓練模型中提取向量從而進行后續的計算,只是在模型迭代過程中,這些向量并不會跟著迭代,因為這些向量于文本綁定住了。但是后來發現這些向量即便跟著迭代也無妨,雖然對于人類而言這些向量迭代更新后在物理世界已經找不到對應的自然語言文本可以表述出意思。但對于AI來講,文本反而無意義,prompt向量隨著訓練會將prompt變得越來越符合業務場景。
假設一句prompt由20個單詞組成,按照GPT3的設定每個單詞映射的向量維度是12288,20個單詞便是245760,理論上需要訓練的參數只有245760個,相比175billion的量級,245760這個數字可以忽略不計,當然也會增加一些額外的輔助參數,但同樣其數量也可忽略不計。
問題來了,這么少的參數真的能逼近?finetuning的效果嗎,當然還是有一定的局限性。如下圖所示,藍色部分代表初版的prompttuning,可以發現prompttuning僅有在模型參數量級達到一定程度是才有效果。雖然這可以解決大多數的場景,但在某些具體垂直領域的應用場景下則未必有用。因為垂直領域的微調往往不需要綜合的LLM預訓練模型,僅需垂直領域的LLM模型即可,但是相對的,模型參數不會那么大。所以隨著發展,改版后的prompttuning效果可以完全取代fine-tuning。下圖中的黃色部分展示的就是prompttuningv2也就是第二版本的prompttuning的效果。
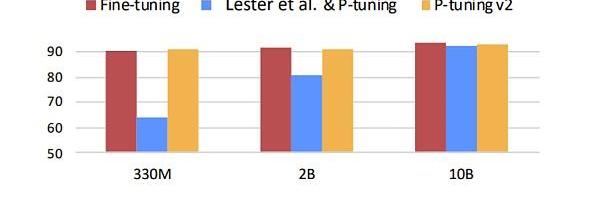
Figure12.Promptlearningparameters
V2的改進是將原本僅在最初層輸入的連續prompt向量,改為在模型傳遞時每一個神經網絡層前均輸入連續prompt向量,如下圖所示。

Figure13.Promptlearningv2
還是以GPT3模型為例,GPT3總從有96層網絡,假設prompt由20個單詞組成,每個單詞映射的向量維度是12288,則所需要訓練的參數量=96*20*12288=23592960。是175billion的萬分之1.35。這個數字雖不足以忽略不計,但相對而言也非常小。
未來可能會有prompttuningv3,v4等問世,甚至我們可以自己加一些創新改進prompttuning,例如加入長短期記憶網絡的設定。(因為原版的prompttuningv2就像是一個大型的RNN,我們可以像改進RNN一般去改進prompttuningv2)。總之就目前而言,prompttuning使得微調LLM變得可行,未來一定會有很多垂直領域的優秀模型誕生。
總結
LargeLanguageModels(LLMs)和Web3技術的整合為去中心化金融領域帶來了巨大的創新和發展機遇。通過利用LLMs的能力,應用程序可以對大量不同數據源進行全面分析,生成實時的投資機會警報,并根據用戶輸入和先前的交互提供定制建議。LLMs與區塊鏈技術的結合還使得智能合約的創建成為可能,這些合約可以自主地執行交易并理解自然語言輸入,從而促進無縫和高效的用戶體驗。
這種先進技術的融合有能力徹底改變DeFi領域,并開辟出一條為投資者、交易者和參與去中心化生態系統的個體提供新型解決方案的道路。隨著Web3技術的日益普及,LLMs創造復雜且可靠解決方案的潛力也在擴大,這些解決方案提高了去中心化應用程序的功能和可用性。總之,LLMs與Web3技術的整合為DeFi領域提供了強大的工具集,提供了有深度的分析、個性化的建議和自動化的交易執行,為該領域的創新和改革提供了廣泛的可能性。
參考文獻

Tags:ROMPROPROMOMPROMEODOGE價格MoonLift Protocolprom幣23年可以買嗎comp幣值得長線持有嗎
來源/messari 編譯/章魚哥 01 摘要 Sui是即將推出的L1智能合約平臺,具有獨特的、以對象為中心的數據模型,這是其擴展網絡吞吐量能力的關鍵.
1900/1/1 0:00:00本文來自Twitter,原文作者:加密KOLMoritzOdaily星球日報譯者|Moni 雖然因為“沒有準備好”而推遲發布,但不出意外的話.
1900/1/1 0:00:00在經歷了表現不俗的2023年一季度后,加密行業并未繼續高歌猛進,4月份再次陷入低迷,有人認為熊市并未完全結束,但也有人認為或許只是暫時市場修正,并不會影響長期發展.
1900/1/1 0:00:00經Odaily星球日報不完全統計,?5月1日-5月7日公布的海內外區塊鏈融資事件共20起,較上周數據有大幅減少,已披露融資總額約為8790萬美元,較上周數據有明顯下降.
1900/1/1 0:00:00來源:AI商業研究所 導讀: GeoffreyHinton被稱為“人工智能教父”,從上世紀80年代開始研究神經網絡,是這個領域從業時間最長的人.
1900/1/1 0:00:00原文作者:xiyu 原文來源:SevenUpDAOORC-20官方文檔:https://docs.orc?20.org/在?ordinals?中,凡是用?json?鑄造銘文然后解讀的.
1900/1/1 0:00:00


