






 BTC/HKD+0%
BTC/HKD+0% ETH/HKD-1.39%
ETH/HKD-1.39% LTC/HKD-0.19%
LTC/HKD-0.19% DOT/HKD+1.95%
DOT/HKD+1.95% ADA/HKD+5.37%
ADA/HKD+5.37% SOL/HKD-0.68%
SOL/HKD-0.68% XRP/HKD-0.75%
XRP/HKD-0.75% DOGE/US+0.59%
DOGE/US+0.59%ChatGPT能否取代Google、百度這樣的傳統搜索引擎?為什么中國不能很快做出ChatGPT?當前,對這些問題的探討大多囿于大型語言模型的技術可行性,忽略或者非常粗糙地估計了實現這些目標背后的經濟成本,從而造成對LLM的開發和應用偏離實際的誤判。
本文作者從經濟學切入,詳細推導了類ChatGPT模型搜索的成本、訓練GPT-3以及繪制LLM成本軌跡的通用框架,為探討LLM成本結構和其未來發展提供了可貴的參考視角。
重點概覽:
LLM驅動的搜索已經在經濟上可行:粗略估計,在現有搜索成本結構的基礎上,高性能LLM驅動搜索的成本約占當下預估廣告收入/查詢的15%。但經濟可行并不意味著經濟合理:LLM驅動搜索的單位經濟性是有利可圖的,但對于擁有超1000億美元搜索收入的現有搜索引擎來說,添加此功能可能意味著超100億美元的額外成本。其他新興的LLM驅動業務利潤很高:比如Jasper.ai使用LLM生成文案,很可能有SaaS服務那樣的毛利率。對于大公司而言,訓練LLM的成本并不高:如今,在公有云中訓練GPT-3僅需花費約140萬美元,即使是像PaLM這樣最先進的模型也只需花費約1120萬美元。LLM的成本可能會顯著下降:自GPT-3發布的兩年半時間里,與GPT-3性能相當的模型的訓練和推理成本下降了約80%。數據是LLM性能的新瓶頸:與增加高質量訓練數據集的大小相比,增加模型參數的數量能獲得的邊際收益越來越小。
#01
動機
LLM的驚人表現引發了人們的廣泛猜想,這些猜想主要包括LLM可能引發的新興商業模式和對現有模式的影響。
搜索是一個有趣的機會,2021年,僅谷歌就從搜索相關的廣告中獲得了超1000億美元的收入。ChatGPT的“病性”傳播已經引發了許多關于搜索領域潛在影響的思考,其中一個就是LLM如今的經濟可行性:
一位聲稱是谷歌員工的人在HackerNews上表示,要想實施由LLM驅動的搜索,需要先將其成本降低10倍。與此同時,微軟預計將在3月份推出LLM版本的Bing,而搜索初創公司如You.com已經將該技術嵌入到了他們的產品之中。最近,《紐約時報》報道,谷歌將在今年推出帶有聊天機器人功能的搜索引擎。更廣泛的問題是:**將LLM納入當前產品和新產品的經濟可行性如何?**在本文中,我們梳理了當今LLM的成本結構,并分析其未來可能的發展趨勢。
#02
重溫LLM工作原理
盡管后續章節的技術性更強,但這篇文章對機器學習熟悉程度不做要求,即使不熟悉這方面內容的人也可以放心閱讀。為了說明LLM的特殊之處,現做一個簡要復習。
語言模型在給定上下文的情況下,對可能輸出的token作出預測:

自回歸語言模型輸入上下文和輸出內容的圖示
為了生成文本,語言模型根據輸出token的概率重復采樣新token。例如,在像ChatGPT這樣的服務中,模型從一個初始prompt開始,該prompt將用戶的查詢作為上下文,并生成token來構建響應。新token生成后,會被附加到上下文窗口以提示下一次迭代。
Layer1區塊鏈LUKSO主網正式上線:5月24日消息,以太坊 ERC-20 標準提出者之一 Fabian Vogelstelle 等人推出的 Layer 1 區塊鏈 LUKSO 宣布主網已正式上線。LUKSO 是基于 Casper PoS 的 EVM 區塊鏈,于 2021 年 2 月通過可逆 ICO 籌集到 1800 萬美元資金。LUKSO 使用 Casper FFG 權益證明,LYXe 驗證者來提議、驗證和擔保區塊的有效性。主網上線后,LYXe 將轉換為 LYX(LUKSO 的原生代幣)。[2023/5/24 15:22:10]
語言模型已經存在了幾十年。當下LLM性能的背后是數十億參數的高效深度神經網絡驅動。參數是用于訓練和預測的矩陣權重,浮點運算的數值通常與參數數量成比例。這些運算是在針對矩陣運算優化的處理器上計算的,例如GPU、TPU和其他專用芯片。
隨著LLM參數量呈指數增長,這些操作需要更多的計算資源,這是導致LLM成本增加的潛在原因。
#03
LLM驅動搜索的成本
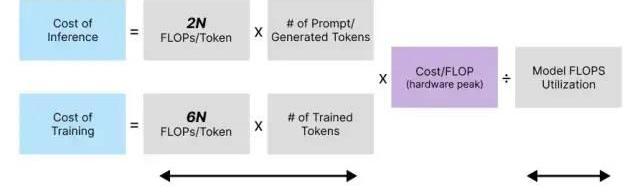
本節,我們將估算運行LLM驅動搜索引擎的成本。應該如何實施這樣的搜索引擎仍是一個活躍的研究領域,我們這里主要考慮兩種方法來評估提供此類服務的成本范圍:
ChatGPTEquivalent:一個在龐大訓練數據集上訓練的LLM,它會將訓練期間的知識存儲到模型參數中。在推理過程中,LLM無法訪問外部知識。容易“幻想”事實。模型知識滯后,僅包含最后訓練日期之前的可用信息。??以上兩點,是這種方法存在的兩大缺陷。2-StageSearchSummarizer:一種架構上類似的LLM,可以在推理時訪問Google或Bing等傳統搜索引擎。在這種方法的第一階段,我們通過搜索引擎運行查詢以檢索前K個結果。在第二階段,通過LLM運行每個結果以生成K個響應,該模型再將得分最高的響應返回給用戶。能夠從檢索到的搜索結果中引用其來源。能獲取最新信息。相比ChatGPTEquivalent,這種方法的優點是:然而,對于相同參數數量的LLM,這種方法需要更高的計算成本。使用這種方法的成本也增加了搜索引擎的現有成本,因為我們在現有搜索引擎的結果上增加了LLM。
一階近似:基礎模型API
最直接的成本估算方法是參考市場上現有基礎模型API的標價,這些服務的定價包括成本的溢價部分,這部分是供應商的利潤來源。一個代表性的服務是OpenAI,它提供基于LLM的文本生成服務。
OpenAI的DavinciAPI由GPT-3的1750億參數版本提供支持,與支持ChatGPT的GPT-3.5模型具有相同的參數數量。現在用該模型進行推理的價格約為0.02美元/750個單詞;用于計算定價的單詞總數包括輸入和輸出。
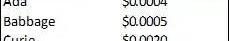
按模型功能劃分的基礎模型API定價(OpenAI)
我們這里做了一些簡單假設來估計將支付給OpenAI的搜索服務費用:
在ChatGPTequivalent的實現中,我們假設該服務平均針對50字的prompt生成400字的響應。為了產生更高質量的結果,我們還假設模型對每個查詢采樣5個響應,從中選擇最佳響應。因此:
Ordinals銘文總量已突破300萬枚:金色財經報道,數據顯示,比特幣NFT協議Ordinals的銘文總量已突破300萬枚。[2023/5/2 14:37:45]
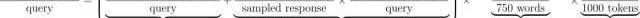
在2-StageSearchSummarizer的實現中,響應生成過程是相似的。然而:
提示明顯更長,因為它同時包含查詢和搜索結果中的相關部分為每K個搜索結果生成一個單獨的LLM響應假設K=10并且搜索結果中的每個相關部分平均為1000個單詞:

假設優化的緩存命中率為30%和OpenAI云服務的毛利率為75%,我們的一階估計意味著:

按照數量級,ChatGPTEquivalent服務的預計云計算成本為0.010美元/次,與公眾評論一致:
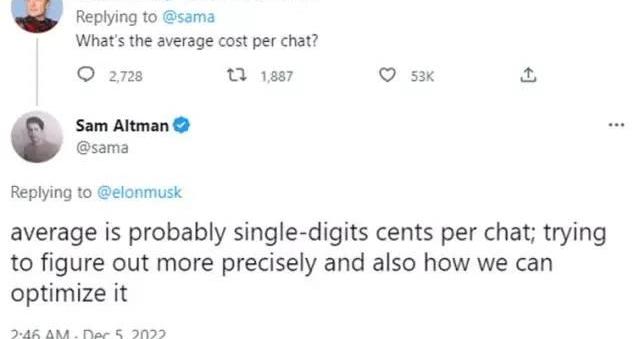
OpenAI首席執行官SamAltman談ChatGPT每次聊天的成本鑒于ChatGPTEquivalent的上述缺點,在實際操作中,LLM驅動搜索引擎的開發者更可能部署2-StageSearchSummarizer變體。
2012年,谷歌搜索主管表示,其搜索引擎每月處理的搜索次數達1000億次。世界銀行數據顯示:全球互聯網普及率已從2012年的34%上升到了2020年的60%。假設搜索量按比例增長,則預計其年均搜索量將達2.1萬億次,與搜索相關的收入將達約1000億美元,平均每次搜索的收入為0.048美元。
換句話說,2-StageSearchSummarizer的查詢成本為0.066美元/次,約為每次查詢收入0.048美元的1.4倍。
通過以下優化,預估成本大約會降至原來的1/4:1、量化2、知識蒸餾3、訓練更小的“計算優化”模型,該模型具有相同的性能假設云計算的毛利率約為50%,與依賴云服務提供商相比,運行自建基礎設施會使成本降低至當前的1/2。綜合以上改進,降低至原有成本的1/8之后,在搜索中融入高性能LLM的成本大約占據當前查詢收入的15%。深度解析:云計算成本
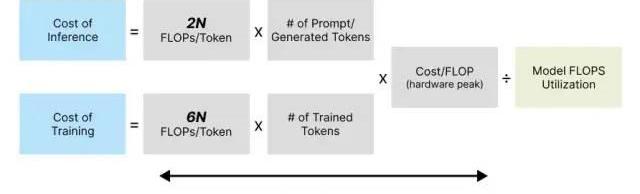
如今,SOTA大型語言模型通常會用到可比較的模型架構,在推理過程中每個token的計算成本約為2N,其中N為模型參數數量。
目前,NVIDIAA100是AWS最具成本效益的GPU選擇,若預定1年使用該GPU,擁有8個A100的AWSP4實例的有效時薪將達19.22美元。每個A100提供峰值312TFLOPSFP16/FP32混合精度吞吐量,這是LLM訓練和推理的關鍵指標。FP16/FP32混合精度是指以16位格式執行操作,而以32位格式存儲信息。由于FP16的開銷較低,混合精度不僅支持更高的FLOPS吞吐量,而且保持精確結果所需的數值穩定性也會保持不變。
Circle CEO:將通過減少銀行存款來保護自己:金色財經報道,在美國聯邦政府出手保護現已倒閉的硅谷銀行儲戶幾天后,Circle首席執行官Jeremy Allaire在接受CNBC采訪時表示,USDC雖恢復錨定但銀行系統風險并未完全消失,他解釋說,美國金融體系受到更廣泛影響的風險似乎是系統性的,我不認為這些風險此時已經完全消散。Circle將通過減少銀行存款來保護自己,從Circle的角度來看,主要的預防措施是讓我們確保盡可能少地暴露在部分準備金銀行系統中的隱含風險。(dailyhodl)[2023/3/16 13:08:23]
假設模型的FLOPS利用率為21.3%,與訓練期間的GPT-3保持一致。因此,對于像GPT-3這樣擁有1750億參數的模型:

我們也應用了基于GCPTPUv4定價相同的計算方法,并得到了相似的結果:
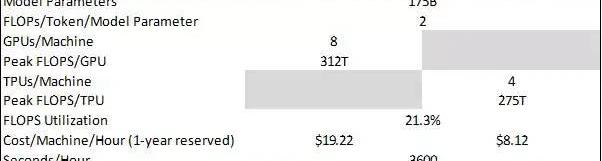
預估GPT-3通過云服務提供商(AWS,?GCP)每處理1000個token所需的推理成本
OpenAI的API定價為0.02美元/1000詞,但我們估計其成本約為0.0035美元/1000詞,占定價的20%左右。這就意味著:**對于一臺一直運行的機器而言,其毛利率約為80%。**這一估算與我們之前設想的75%毛利率大致相同,進而為ChatGPTEquivalent和2-StageSearchSummarizer搜索成本估算提供了合理性驗證。
#04
訓練成本如何?
另一個熱門話題是GPT-3或最新的LLM的訓練成本。基于參數數量和token數量,我們構建了一個用于估算計算成本的框架,雖然稍作修改,但同樣適用于此:
每個token的訓練成本通常約為6N,其中N是LLM的參數數量假設在訓練過程中,模型的FLOPS利用率為46.2%,與在TPUv4芯片上進行訓練的PaLM模型一致。1750億參數模型的GPT-3是在3000億token上進行訓練的。谷歌使用了GCPTPUv4芯片來訓練PaLM模型,若我們現在也像谷歌那樣做,那么如今的訓練成本僅為140萬美元左右。

此外,我們還將該框架應用到一些更大的LLM模型中,以了解其訓練成本。

預估LLM在GCPTPUv4芯片上的訓練成本
#05
繪制成本軌跡的通用框架
為了推導LLM的推理成本/訓練成本,我們總結了如下框架:
美聯儲2月加息25BP的概率為76%:1月9日消息,據CME“美聯儲觀察”:美聯儲2月加息25個基點至4.50%-4.75%區間的概率為76.6%,加息50個基點的概率為23.4%;到3月累計加息25個基點的概率為12.2%,累計加息50個基點的概率為68.2%,累計加息75個基點的概率為19.7%。[2023/1/9 11:01:49]

密集激活純解碼器LLM模型Transformer的推理成本和訓練成本
因此,我們假設LLM的架構相似,那么推理成本和訓練成本將根據上述變量的變化而變化。雖然我們會詳細考慮每個變量,但是以下部分才是關鍵點:
自2020年GPT-3發布以來,使用與GPT-3一樣強大的模型進行訓練和推理的成本大大降低,低于先前的五分之一。

相比2020年推出的GPT-3,與其性能對等的模型的推理與訓練成本降低情況總結
參數數量效率:巨型語言模型參數每年增長10倍的神話
考慮到過去5年中模型參數呈指數增長,我們普遍猜測:下一代LLM模型很可能是萬億參數模型:

LLM中模型參數數量的增長
雖然LLM的參數數量每年約增長10倍,但是大多數模型訓練數據集的大小并沒有顯著變化:

所選LLM的模型參數數量與訓練token數量(訓練計算最優大語言模型)
然而,最新文獻表明,假設計算資源和硬件利用率保持不變,關注擴展參數數量并不是性能最大化的最佳方式:

GoogleDeepMind的研究人員將一個參數函數擬合到他們的實驗結果中,發現參數數量N的增速應與訓練token數量D的增長速度大致相同,從而讓模型損失L實現最小化:
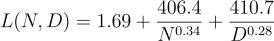
模型損失的參數函數(訓練計算最優大語言模型)
研究人員還訓練了一個名為Chinchilla的模型。雖然該模型的計算資源與Gopher相同,但是該模型是在1.4萬億token上進行訓練的而非3000億token。Chinchilla的性能明顯優于擁有相同FLOPs預算的大型模型,從而證明了大多數LLM過度支出了計算量和對數據的渴望。
澳大利亞參議員起草針對穩定幣、數字人民幣監管新法案:金色財經報道,澳大利亞自由黨參議員Andrew Bragg發布一項新法案草案,旨在打擊數字資產交易所、穩定幣和中國央行數字貨幣e-Yuan。Bragg在9月18日的一份聲明中表示,“澳大利亞必須跟上全球數字資產監管競賽的步伐”,因為“議會必須推動法律改革”。
新法案草案名為《2022年數字資產(市場監管)法案》,要求引入數字資產交易所、數字資產托管服務、穩定幣發行人的許可證,以及對澳大利亞e-Yuan服務商的披露要求。(Cointelegraph)[2022/9/19 7:05:39]

通過訓練數據大小與模型參數來預測模型損失(錯誤更少:Chinchilla的自然環境含義)
雖然Chinchilla的參數比GPT-3少60%,但是其性能遠遠優于擁有1750億參數的GPT-3模型。實際上,即使我們用與GPT-3相同的3000億token數據集去訓練一個萬億參數模型,仍可以預見該模型的表現不如Chinchilla:
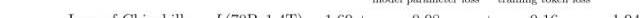
萬億參數模型相應損失項的相對量級也表明,通過增加模型大小獲得的邊際效益低于增加數據量獲得的邊際效益。
展望未來,我們不會繼續擴大模型參數數量,而是將增量計算資源轉移到質量相當的更大數據集上進行訓練,以獲得極佳的性能。Cost/FLOP效率
對于訓練LLM而言,最重要的硬件性能指標是可實現的混合精度FP16/FP32FLOPS。改進硬件旨在實現成本最小化,同時使得峰值FLOPS吞吐量和模型FLOPS利用率實現最大化。
雖然這兩個部分在硬件開發中密不可分,但為了讓分析變得更簡單,本節重點關注吞吐量,下一節再討論利用率。
目前,我們已經通過查看云實例定價估算了Cost/FLOP效率。為了進行下一步探究,我們估算了運行以下機器的成本。主要包括以下兩個方面:1)硬件購買2)能源支出。為說明這一點,我們再來看看GPT-3(一款由OpenAI推出的模型,該模型在MicrosoftAzure的10000個V100GPU上訓練了14.8天):

2020年用英偉達V100GPU訓練GPT-3的成本(碳排放與大型神經網絡訓練)
黃仁勛定律指出,在硬件成本方面,GPU的增長速度比五年前快了25倍。在訓練LLM的背景下,GPU的性能得到了很大提升,這很大程度上得益于張量核心)。此外,GPU不再將矢量作為計算原語,而是轉為矩陣,從而實現了性能更好、效率更高的混合精度計算。
2016年,NVIDIA通過V100數據中心GPU首次推出了張量核心。與最初引入的張量核心相比,雖然這一改進不太明顯,但是每一代張量核心都進一步提高了吞吐量。如今,對于用于訓練LLM的數據中心GPU,我們仍能看到每一代GPU的吞吐量都提升了50%。

數據中心GPUFP16/FP32吞吐量/美元(NVIDIA)
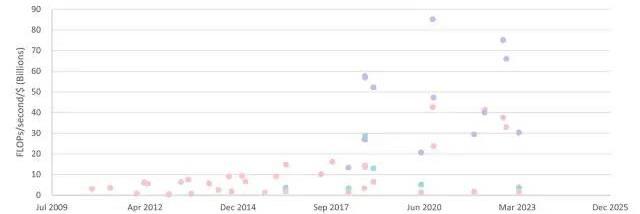
桌面GPU和數據中心GPU、按精度劃分的吞吐量/美元(英偉達,深度學習推理中的計算和能源消耗趨勢)
桌面GPU和數據中心GPU、按精度劃分的吞吐量/美元(英偉達,深度學習推理中的計算和能源消耗趨勢)
能源效率提升得更快。現在我們可以看到,用于訓練LLM的數據中心GPU的代際吞吐量/瓦特提高了80%:

數據中心GPUFP16/FP32吞吐量/瓦特(英偉達)
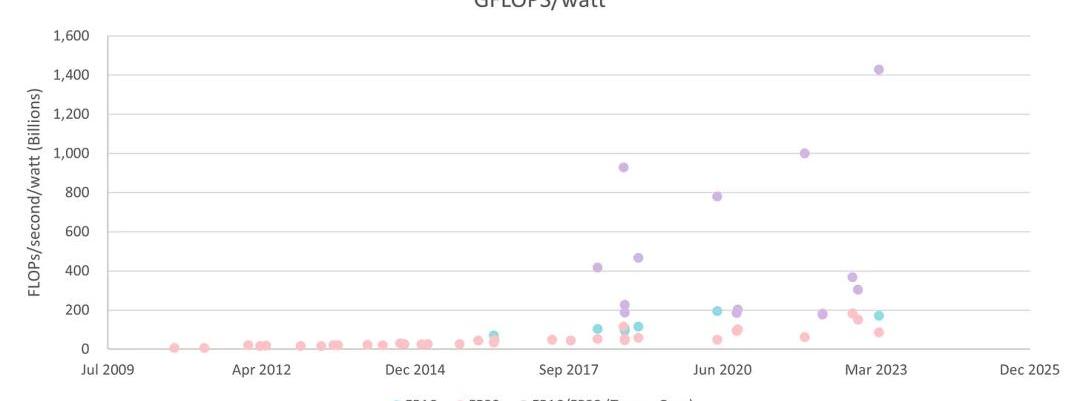
按精度劃分的桌面和數據中心GPU吞吐量/瓦特
僅從V100到即將推出的H100的改進來看,我們預計內部訓練成本將降低58%。

目前使用英偉達H100GPU訓練GPT-3的成本
展望未來,我們預測,**隨著硬件設計的不斷創新,硬件成本和能效將逐步改進。**例如,從V100到A100GPU,NVIDIA添加了稀疏特性,這進一步將某些深度學習架構的吞吐量提高了2倍。NVIDIA正在H100中添加對FP8數據類型的本地支持,當與推理量化等現有技術相結合時,可以進一步提高吞吐量。
此外,TPU和其他專用芯片的出現從根本上重塑了深度學習用例的芯片架構。谷歌的TPU建立在脈動陣列結構之上,可顯著減少寄存器使用,提高吞吐量。正如下一節將提到的,隨著我們將訓練和推理擴展到大型參數模型,最近許多硬件都著力于提高利用率。
硬件利用率提升
出于內存需求,LLM訓練的主要挑戰之一就是將這些模型從單個芯片擴展到多個系統和集群級別。在典型的LLM訓練中,設置保存優化器狀態、梯度和參數所需的內存為20N,其中N是模型參數數量。
因此,BERT-Large僅需6.8GB內存,就可輕松裝入單個桌面級GPU。另一方面,對于像GPT-3這樣的1750億參數模型,內存要求轉換為3.5TB。同時,NVIDIA最新的數據中心GPU僅包含80GB的高帶寬內存(HBM),這表明至少需要44個H100才能滿足GPT-3的內存要求。此外,即使在10000個V100GPU上訓練GPT-3也需要14.8天。
因此,即使我們增加用于訓練的芯片數量,FLOPS利用率也仍然需要保持高水平,這一點至關重要。
**硬件利用率的第一個維度是在單芯片層面。**在單個A100GPU上訓練GPT-2模型時,硬件利用率達35.7%。事實證明,片上內存和容量是硬件利用的瓶頸之一:處理器內核中的計算需要重復訪問HBM,而帶寬不足會抑制吞吐量。同樣,有限的本地內存容量會迫使從延遲較高的HBM進行更頻繁的讀取,從而限制吞吐量。
硬件利用率的第二個維度與芯片到芯片的擴展有關。訓練像GPT-3這樣的LLM模型需要跨多個GPU對模型和數據進行劃分。正如片上存儲器的帶寬可能成為硬件利用的瓶頸一樣,芯片間互連的帶寬也可能成為硬件利用的限制因素。隨著V100的發布,NVIDIA的NVLink實現了每個GPU300GB/s的帶寬。對于A100來說,寬帶速度實現了600GB/s。
硬件利用率的最后一個維度是系統到系統的擴展。一臺機器最多可容納16個GPU,因此擴展到更多數量的GPU要求跨系統的互連不能成為性能瓶頸。為此,Nvidia的InfinibandHCA在過去3年中將最大帶寬提高了2倍。
在第二和第三個維度上,軟件劃分策略是硬件有效利用的關鍵考慮因素。通過結合模型和數據并行技術,2022年使用MT-NLG的Nvidia芯片集群級別的LLM訓練的模型FLOPS利用率達到了30.2%,而使用GPT-3的模型FLOPS利用率在2020年只有21.3%:
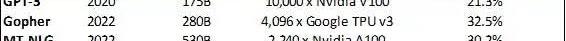
選擇LLM的模型FLOPS利用率
選擇LLM的模型FLOPS利用率
TPU等專用硬件實現了更高的效率。
谷歌5400億參數的PaLM模型在TPUv4芯片上實現了46.2%的模型FLOPS利用率,是GPT-3訓練利用率的2.2倍FLOPS利用率的提高得益于更高效的并行訓練以及從根本上TPU具有完全不同的架構。該芯片的脈動陣列結構和每個內核的顯著的本地內存密度降低了高延遲全局內存的讀取頻率。
同樣地,我們可以看到**Cerebras、Graphcore**和SambaNova等公司在處理器中分配了更多的共享內存容量。展望未來,我們預計其他新興創新,例如將芯片擴展到晶圓級以減少延遲/增加帶寬,或通過可編程單元優化數據訪問模式等將進一步推動硬件利用率的發展。
#06
大型語言模型即將迎來全盛時期
據《紐約時報》近日報道,谷歌宣稱ChatGPT是其搜索業務的“紅色警報”,它的搜索量呈病式發展。
從經濟角度來看,通過粗略估算,將高性能LLM納入搜索將花費約15%的查詢收入,這表明該技術的部署已經切實可行。然而,谷歌的市場主導地位阻礙了它成為這方面的先行者:谷歌目前的搜索收入為1000億美元,將高性能LLM納入搜索會使谷歌的盈利能力減少一百多億美元。
另一方面,也就難怪微軟會計劃將大語言模型納入Bing了。盡管LLM支持的搜索成本高于傳統搜索,并且與谷歌相比,微軟搜索引擎的市場份額要低得多,但是微軟并未虧損。因此,如果微軟能夠成功地從谷歌手中奪取搜索市場份額,那么即使現有查詢成本更高,微軟仍然能夠獲得極高的利潤。
有趣的是,對于其他產品,通過部署LLM已經可以通過SaaS來盈利。例如,最近估值為15億美元、使用LLM生成文案的Jasper.ai收費為82美元/100000字。使用OpenAI的DavinciAPI定價為0.02美元/1000個token,即使我們對多個響應(response)進行采樣,毛利率也可能遠高于75%。
同樣令人驚訝的是,如今在公有云中僅需約140萬美元即可對GPT-3進行訓練,而且即使是SOTA模型的訓練成本也不會太高。在過去的兩年半里,類似GPT-3等模型的訓練成本下降了80%以上,高性能大語言模型的訓練成本將進一步降低。
換句話說,訓練大語言模型并不便宜,但也沒那么燒錢,訓練大語言模型需要大量的前期投入,但這些投入會逐年獲得回報。更近一步,Chinchilla論文表明,在未來,相比資金,高質量數據會成為訓練LLM的新興稀缺資源之一,因為擴展模型參數數量帶來的回報是遞減的。
2月14日,App-?Rollup擴容解決方案項目?Caldera?宣布在兩輪融資中合計籌資900?萬美元,兩輪融資分別由紅杉資本和?DragonflyCapital?領投.
1900/1/1 0:00:00注:本文為NFTGoNFT年報的第三部分相關閱讀:NFTGo:NFT行業2022年發生了什么?NFTGo:縱覽NFT影響力趨勢與宏觀市場概況NFT微觀趨勢及現象分析 NFT項目發行趨勢 發行數量.
1900/1/1 0:00:00注:本文來自@zgwfather推特,MarsBit整理如下:1/今天正好研究了下如何讓自己的資金使用效率最大化,同時分享一下我在幣圈的風險資產配置和套利思路,也會介紹幾個我喜歡的新興項目.
1900/1/1 0:00:00Arbitrum?是目前市場上最受關注的以太坊擴展解決方案之一。據Defillama數據顯示,其鎖倉量自2022年7月以來一直處于穩步上漲趨勢,當前已達到約138億美元.
1900/1/1 0:00:002月10日,2023年閩侯縣文化旅游推介大會暨美食嘉年華盛大開幕推介大會上,福建省區塊鏈協會副會長單位美亞文旅與閩侯縣大湖鄉人民政府簽訂戰略合作協議,首期雪峰山城建設投資5000萬元.
1900/1/1 0:00:00厭倦了對于新項目的錯過,也不知道如何發現Alpha,沒關系,加密研究員FungiAlpha撰文介紹了近期需要關注的潛力項目,BlockBeats整理和編譯如下:以下是我們發現的一些潛力項目.
1900/1/1 0:00:00


